
MongoDB
Centos7安装mongodb
前往官网下载mongodb的tgz包
选择centos7下的4.4版本tgz包 –> 官网
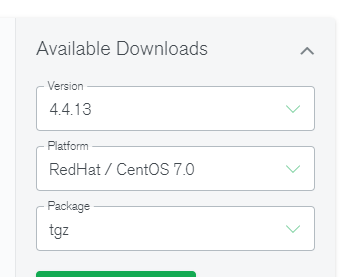
上传至服务器【目录自选】
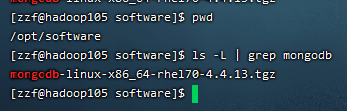
使用tar -zxvf 目标压缩包 -C 目标目录 |
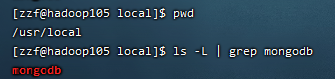
创建数据库目录
默认情况下 MongoDB 启动后会初始化以下两个目录:
- 数据存储目录:/var/lib/mongodb
- 日志文件目录:/var/log/mongodb
我们在mongodb目录下创建对应对应的数据以及日志文件
cd /usr/local/mongodb |
前台启动
MongoDB的默认启动方式为前台启动。所谓的前台启动就是MongoDB启动进程后会占用当前的终端窗口。
切换至指定目录 |
--dbpath:指定数据文件存放目录--logpath:指定日志文件,注意指定文件不是目录--logappend:使用追加的方式记录日志--port:指定端口,默认为27017--bind_ip:绑定服务IP,若绑定127.0.0.1,则只能本机访问,默认为本机地址
后台启动
切换至指定目录 |
如果想关掉后台服务只需要尾部添加--shutdown
配置文件
#数据文件存放目录 |
以配置文件方式启动
bin/mongod -f bin/mongodb.conf |
如果要关闭同样尾部添加--shutdown即可
MongoDB函数关闭
连接MongoDB服务后,切换admin数据库,并使用相关函数关闭服务
#连接mongodb |
配置环境变量
vim /etc/profile |
MongoDB用户与权限管理
常用权限
| 权限 | 说明 |
|---|---|
| read | 允许用户读取指定数据库 |
| readWrite | 允许用户读写指定数据库 |
| userAdmin | 允许用户向system.users集合写入,可以在指定数据库里创建、删除和管理用户 |
| dbAdmin | 允许用户在指定数据库中执行管理函数,如索引创建、删除,查看统计或访问system.profile |
| clusterAdmin | 必须在admin数据库中定义,赋予用户所有切片和复制集相关函数的管理权限 |
| readAnyDatabase | 必须在admin数据库中定义,赋予用户所有数据库读权限 |
| readWriteAnyDatabase | 必须在admin数据库中定义,赋予用户所有数据库读写权限 |
| userAdminAnyDatabase | 必须在admin数据库中定义,赋予用户所有数据库userAdmin权限 |
| dbAdminAnyDatabase | 必须在admin数据库中定义,赋予用户所有数据库dbAdmin权限 |
| root | 必须在admin数据库中定义,超级站账号,超级权限 |
创建管理用户
切换数据库
#查看所有数据库 |
查看用户
#查看用户 |
创建用户
#创建用户 |
在配置文件中添加如下信息,代表开启认证
#开启身份认证 |
重启服务
身份认证
mongo |
创建普通用户
需求:创建一个test数据库,给这个数据库添加一个用户,用户名为testuser,密码为123456。并授予用户对test数据库的读写操作权限。
管理员登录数据库
mongo |
创建数据库
#如果没有数据库,通过use test 也会进行创建test数据库,并进入 |
创建用户
#创建用户 |
身份认证
use test |
更新用户
更新用户权限
如果我们需要对已存在的角色进行角色修改,可以使用db.updateUser()函数来更新用户角色。注意:执行该函数需要当前用户具有userAdmin或userAdminAmyDataBase或root角色。
#更新用户权限 |
更新密码
更新用户密码有以下两种方式,更新密码时需要切换到该用户所在数据库。注意:需要使用具有userAdmin或userAdminAnyDatabase或root角色的用户执行:
- 使用
db.updateUser("用户名",{"pwd":"新密码"})函数更新密码 - 使用
db.changeUserPassword("用户名","新密码")函数更新密码
删除用户
通过db.dropUser()函数可以删除指定用户,删除成功以后会返回true。删除用户时需要切换到该用户所在的数据库。注意:需要使用具有userAdmin或userAdmiAnyDatabase或root角色的用户才可以删除其他用户。
mongo |
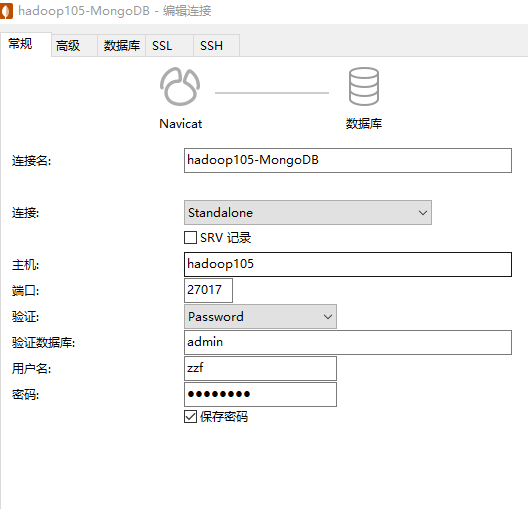
GUI
关于MongoDB的GUI有很多种,本学习使用Navicat 15
Navicat 15
MongoDB的集合操作
Database操作
创建数据库
利用use test切换数据库,如果没有则创建并切换
查看数据库
PS:不同的角色显示的数据库不同
使用show dbs或show databases查看所有数据库
删除数据库
删除数据库需要切换到需要删除的数据库中,且登录用户具有dbAdminAnyDatabase权限,执行db.dropDatabase()
Collection操作
MongoDB中的集合是一组文档的集,相当于关系型数据库中的表(table)
创建集合
db.table1创建集合db.table1.insert()该指令可以创建集合并且插入文档
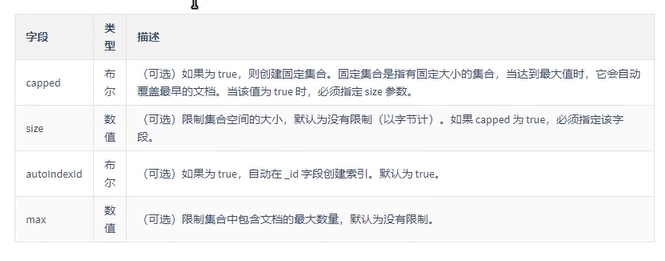
MongoDB使用db.createCollection()函数来创建集合。
语法格式:db.createCollection(name,option)。
- name:要创建的集合名称
- option:可选参数,指定有关内存大小和索引的选项
查看集合
show tables或show collections查看集合
删除集合
通过db.COLLECTION_NAME.drop()删除集合
#示例 |
Document操作
插入文档
单条插入
可以使用insert/insertOne/save插入单条文档:
db.c1.insert({"name":"a"})db.c1.insertOne({"name":"a"})db.c1.save({"name":"a"})如果指定了_id字段则为修改【如果没有也为添加】,反之等同于insert()方法
如果JSON格式的文档很长,我们也可以用一个变量操作
#示例 |
批量插入
可以使用insert/insertMany/save插入多条文档,区别在于把单挑插入时函数参数的对象类型{}变成数组类型[{},{}]:
db.c1.insert([{name:"a"},{name:"b"}])db.c1.insertMany([{name:"a"},{name:"b"}])db.c1.save([{name:"a"},{name:"b"}])
#示例代码 |
更新文档
通过update系列函数或则save函数可以更新集合中的文档。我们来详细看下update函数的使用,上面已经讲过save函数update()函数用于更新已存在的文档。语法格式如下:
db.COLLECTION_NAME.update(query,update,options) |
query:update的查询条件,类似SQL update 语法中的where部分update:update的对象和一些更新的操作符(如$,$inc,$unset,$push,$pop,$pull,$pullAll,$rename)等,也可以理解为SQL update语法中的set部分。upsert:可选,如果不存在update的文档,是否插入该文档。true为插入,默认是false,不插入。multi:可选,是否批量更新。true表示按条件查询出来的多条记录全部更新,false只更新找到的第一条记录,默认是false。
#示例代码 |
更新操作符
$set操作符(需要记忆)$set操作符:用于指定一个键并更新键值,若键不存在并创建。只能修改第一个document
语法格式:db.COLLECTION_NAMAE.update({查询条件},{更新操作符:{更新内容}})$set的作用总结:- 只修改特定的Field,解决update默认修改整个document情况
db.c1.update({name:"张三"},{$set:{name:"王五"}})
- 默认只修改符合条件第一个document,如果需要全部修改,添加更新参数multi:true
db.c1.update({name:"张三"},{$set:{name:"王五"}},{mutli:true})
- 如果Field不存在,可以新建一个Field
db.c1.update({name:”张三”},{$set:{sex”男”}})
- 只修改特定的Field,解决update默认修改整个document情况
$inc操作符:可以对文档的某个值为数字型(只能为满足要求的数字)的键及增删操作。如果给定负数表示减少。
把王五的年龄减少5岁db.c1.update({name:"王五"},{$inc:{age:-5}})
$unset操作符:主要是用来删除键。让键的值为空。在编写命令时$unset理field取任意值,无论给定什么值都表示删除。$push操作符:向文档的某个数组类型的键添加一个数组元素,不过滤重复的数据。添加时键存在,要求键值类型必须是数组;键不存在,则创建数组类型的键。$pop操作符:删除数据元素。可取只能是1或-1。1表示尾部删除,-1表示头部删除$pull操作符:从数组中删除满足条件的元素,只要满足条件都删除$pullAll操作符:可以设置多个条件$rename操作符:对键盘进行重新命名。任何类型的键都能重命名。
删除文档
MongoDB remove()函数是用来移除集合中的数据,其语法格式如下所示:
db.user.remove(<query>,{justOne:<boolean>}) |
参数说明:
- query:(可选)删除的文档的条件。
- justOne:(可选)如果设为true,则只删除一个文档,False删除所有匹配的数据
等价于db.user.deleteOne(<query>):删除符合条件的第一个文档db.user.remove({"name":"lisa"},{justOne:true})
db.user.deleteOne({"name":"lisa"})
删除所有数据命令:
db.user.remove({}) |
查询文档
查询所有
MongoDB 查询数据的语法格式如下:
db.user.find()#等同于db.user.find({}) |
find()方法以非结构化的方式来显示所有文档
如果你需要以易读的方式来读取数据,可以使用pretty()方法,语法格式如下:
格式化-》返回的内容易读
db.user.find().pretty() |
pretty()方法以格式化的方式来显示所有文档
比较运算
注意:在MongoDB中,用到方法逗得用$符号开头
=,!=(‘$ne’),>(‘$gt’),<(‘$lt’),>=(‘$gte’),<=(‘$lte’)
#1. select * from user where id = 3 |
逻辑运算
MongoDB 中字典内用逗号分隔多个条件是and关系,或则直接用$and,$or,$not(与或非)
#逻辑运算:$and,$or,$not |
成员运算
成员运算无非in 和 not in,MongoDB中形式为$in、$nin
#1. select * from user where age in(1,2,3) |
$type操作符
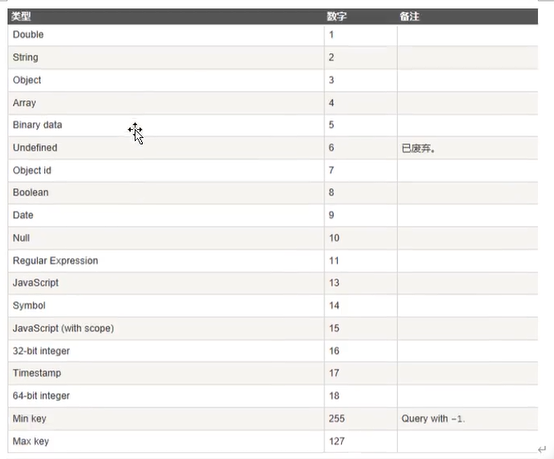
#查询name是字符串类型的数据 |
正则
#1. select * from user where name regexp '^z.*?(u|i)$'; |
投影
MongoDB投影意思是只选择必要的数据而不是选择一整个文档的数据
在MongoDB中,当执行find()方法,那么它会显示一个文档所有字段。要限制这一点,需要设置字段列表值1或0
#1. select name,age from user where id =3 ; |
数组
#查询数组相关 |
排序
在MongoDB中使用sort()方法对数据进行排序,sort()可以通过参数指定排序的字段,并且使用1和-1来指定排序的方式,其中1为升序排列,而-1是用于降序排列
#按姓名正序 |
分页
limit表示取多少个document,skip代表跳过几个document
分页公式:db.user.find().skip((pageNum-1)*pageSize).limit(pageSize)
db.user.find().limit(2).skip(0)#前2个 |
统计
#查询_id大于3的人数 |
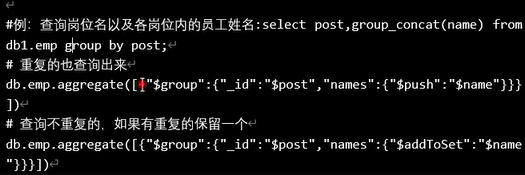
聚合
我们在查询时肯定会用到聚合,在MongoDB中聚合为aggregate,聚合函数主要用到$match,$group,$avg,$project,$concat,可以加$match也可以不加$match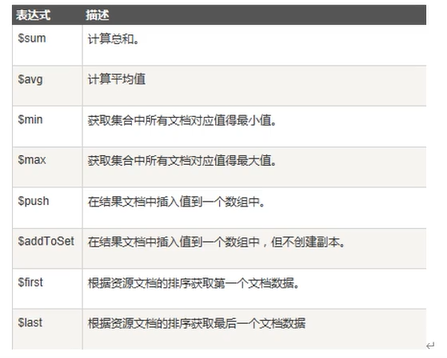
Aggregate语法

$match和$group
相当于sql语句的where和group by
{“$match”:{“字段”:”条件”}},可以使用任何常用查询操作符$gt,$lt,$in等
{“$group”:{“_id”:分组字段,”新的字段名”:聚合操作符}}
{"$match":{"字段":"条件"}},可以使用任何常用查询操作符$gt,$lt,$in等 |

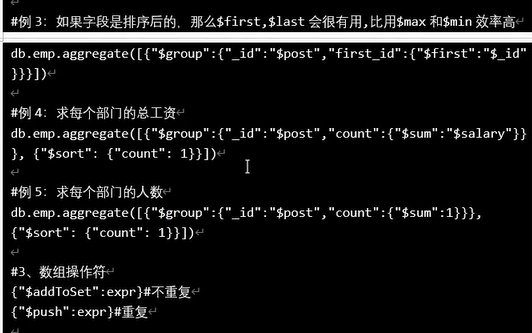
$project

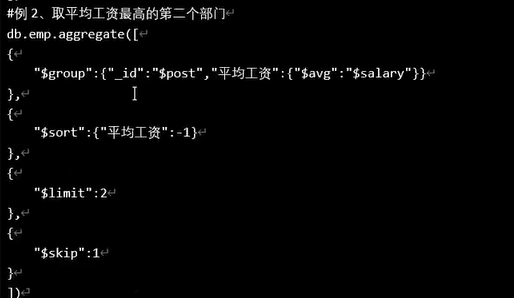
$sort和$limit和$skip

$sample

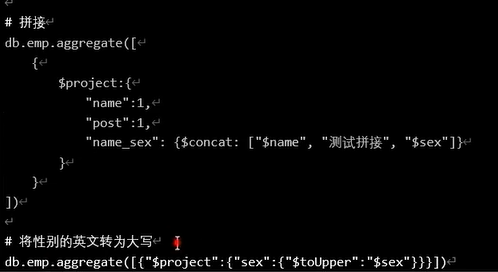
$concat和$substr和$toLower和$toUppper

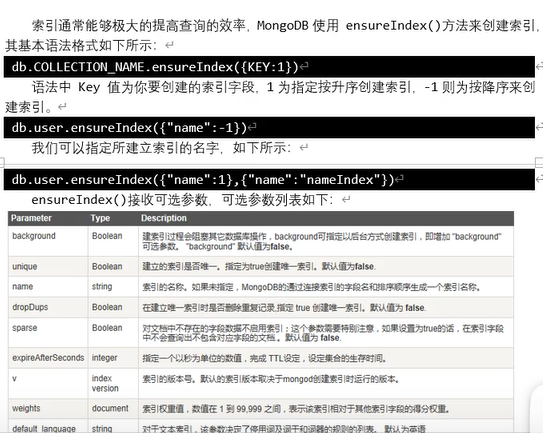
索引
创建索引
查询索引

删除索引

SpringDataMongoDB
创建一个SpringBoot的maven项目
导入pom的依赖
<dependency> |
编写连接字符串
application.properties
#application.properties的配置写法 |
编写一个实体类
| 注解 | 说明 |
|---|---|
| @Id | 用于标记id字段,没有标记此字段的实体也会自动生成id字段,但是我们无法通过实体来获取id。id建议使用ObjectId类型来创建。 |
| @Document | 用于标记此实体类是mongodb集合映射类。可以使用collection参数指定集合名称。特别需要注意的是如果实体类没有为任何字段创建索引将不会自动创建集合。 |
| @Indexed | 用于标记为某一字段创建索引。direction参数可以指定排序方向,升或降序。 |
| @CompoundIndex | 用于创建复合索引。def参数可以定义复合索引的字段及排序方向。 |
| @Transient | 被该注解标注的,将不会被录入到数据库中。只作为普通的javaBean属性。 |
| @PersistenceConstructor | 用于声明构造函数,作用是把从数据库取出的数据实例化为对象。 |
| @Field | 用于指定某一个字段映射到数据库中的名称。 |
| @DBRef | 用于指定与其他集合的级联关系,但是需要注意的是并不会自动创建级联集合。 |
|
编写一个dao接口继承MongoRepository<实体类,主键类型>
public interface UserDao extends MongoRepository<User,String> { |
测试
SpringData规则
public interface CommentRepository extends MongoRepository<Comment,String > { |
想必大家在学习MongoDB会看到类似的接口,写着方法名,没有写相应实现类也没有对应xml就能实现调用。后来根据学习与探究发现底层是使用SpringData的规则应用,以下是学习记录。
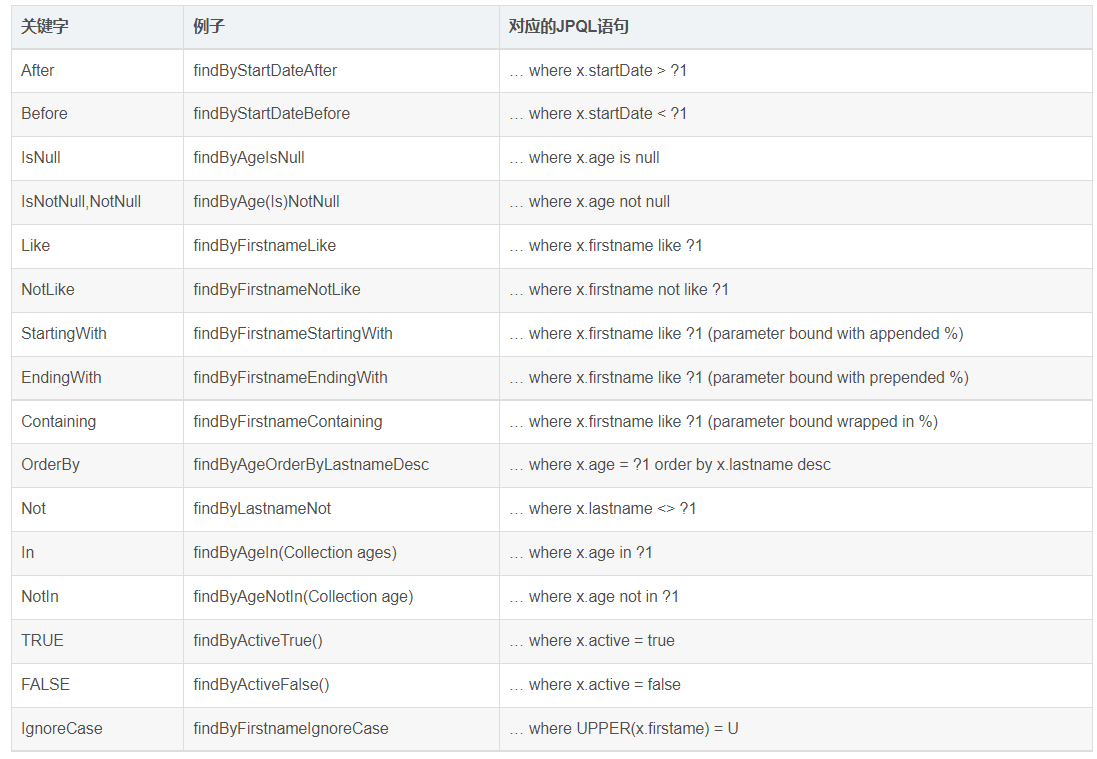
方法命名规则查询
顾名思义,方法命名规则查询就是根据方法的名字,就能创建查询。只需要按照SpringData JPA提供的方法。
命名规则定义方法的名称,就可以完成查询工作。
SpringData JPA在程序执行的时候会根据方法名称进行解析,并自动生成查询语句进行查询.
按照SpringData JPA定义的规则,查询方法以findBy开头,涉及条件查询时,条件的属性用条件关键字连接,要注意的是:条件属性首字母需大写。框架在进行方法名解析时,会先把方法名多余的前缀截取掉,然后对剩下部分进行解析 。
List<Article> findByTitle(String title); |

定义查询方法
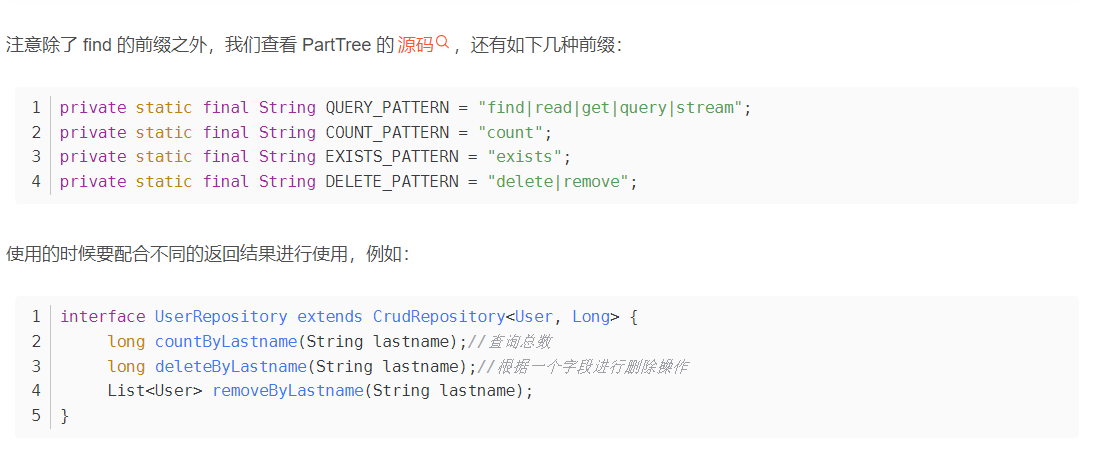
存储库代理有两种从方法名称派生特定于 Store 的查询的方式:
- 通过直接从方法名称派生查询。
- 通过使用手动定义的查询。
可用选项取决于实际 Store。但是,必须有一个策略来决定要创建的实际查询。下一节将介绍可用的选项。
查询查询策略
以下策略可用于存储库基础结构来解决查询。使用 XML 配置,您可以通过query-lookup-strategy属性在名称空间中配置策略。对于 Java 配置,可以使用Enable${store}Repositories注解的queryLookupStrategy属性。某些数据存储可能不支持某些策略。
- CREATE尝试从查询方法名称构造特定于 Store 的查询。通用方法是从方法名称中删除一组给定的众所周知的前缀,然后解析该方法的其余部分。您可以在“ Query Creation”中阅读有关查询构造的更多信息。
- USE_DECLARED_QUERY尝试查找已声明的查询,如果找不到则抛出异常。该查询可以通过某处的 Comments 定义,也可以通过其他方式声明。请查阅特定 Store 的文档以找到该 Store 的可用选项。如果存储库基础结构在引导时找不到该方法的声明查询,则它将失败。
- CREATE_IF_NOT_FOUND(默认)组合了CREATE和USE_DECLARED_QUERY。它首先查找一个声明的查询,如果找不到声明的查询,它将创建一个基于名称的自定义方法查询。这是默认的查找策略,因此,如果未显式配置任何内容,则使用该策略。它允许通过方法名称快速定义查询,还可以通过根据需要引入已声明的查询来自定义调整这些查询。
查询创建
内置在 Spring Data 存储库基础结构中的查询构建器机制对于在存储库实体上构建约束查询很有用。该机制从方法中剥离前缀find…By,read…By,query…By,count…By和get…By,并开始解析其余部分。 Introduction 子句可以包含其他表达式,例如Distinct,以在要创建的查询上设置不同的标志。但是,第一个By充当分隔符,以指示实际标准的开始。在最基本的级别上,您可以定义实体属性的条件,并将它们与And和Or串联。以下示例显示了如何创建许多查询:
例子 13.从方法名查询创建
public interface PersonRepository extends Repository<User, Long> { |
解析该方法的实际结果取决于您为其创建查询的持久性存储。但是,需要注意一些一般事项:
表达式通常是属性遍历,并带有可串联的运算符。您可以将属性表达式与AND和OR结合使用。您还将获得对属性表达式的支持,例如Between,LessThan,GreaterThan和Like。支持的运算符可能因数据存储而异,因此请参考参考文档的相应部分。
方法解析器支持为单个属性(例如findByLastnameIgnoreCase(…))或支持忽略大小写的类型的所有属性(通常为String instance_,例如findByLastnameAndFirstnameAllIgnoreCase(…))设置IgnoreCase标志。是否支持忽略大小写可能因 Store 而异,因此请参考参考文档中有关 Store 特定查询方法的相关部分。
您可以通过将OrderBy子句附加到引用属性的查询方法并提供排序方向(Asc或Desc)来应用静态排序。要创建支持动态排序的查询方法,请参阅“ 特殊参数处理”。
属性表达式
如上例所示,属性表达式只能引用被管实体的直接属性。在查询创建时,您已经确保已解析的属性是托管域类的属性。但是,您也可以通过遍历嵌套属性来定义约束。考虑以下方法签名:
List<Person> findByAddressZipCode(ZipCode zipCode); |
假设Person具有Address和ZipCode。在这种情况下,该方法将创建属性遍历x.address.zipCode。解析算法首先将整个部分(AddressZipCode)解释为属性,然后在域类中检查具有该名称的属性(未大写)。如果算法成功,它将使用该属性。如果不是,该算法将驼峰案例部分的源从右侧分为头和尾,并尝试找到相应的属性,在我们的示例中为AddressZip和Code。如果该算法找到了具有该头部的属性,则将其取为尾部,并 continue 从此处开始构建树,以刚才描述的方式将尾部向上拆分。如果第一个分割不匹配,则算法将分割点移到左侧(Address,ZipCode)并 continue。
尽管这在大多数情况下应该可行,但算法可能会选择错误的属性。假设Person类也具有addressZip属性。该算法将在第一轮拆分中已经匹配,选择错误的属性,然后失败(因为addressZip的类型可能没有code属性)。
要解决这种歧义,您可以在方法名称中使用_来手动定义遍历点。因此,我们的方法名称如下:
List<Person> findByAddress_ZipCode(ZipCode zipCode); |
因为我们将下划线字符视为保留字符,所以我们强烈建议您遵循以下标准 Java 命名约定(即,在属性名称中不使用下划线,而使用驼峰大小写)。
特殊参数处理
要处理查询中的参数,请定义方法参数,如前面的示例所示。除此之外,基础架构还可以识别某些特定类型(例如Pageable和Sort),以将分页和排序动态应用于您的查询。下面的示例演示了这些功能:
例子 14.在查询方法中使用Pageable,Slice和Sort
Page<User> findByLastname(String lastname, Pageable pageable); |
第一种方法使您可以将org.springframework.data.domain.Pageable实例传递给查询方法,以将分页动态添加到静态定义的查询中。 Page知道可用元素和页面的总数。它是通过基础结构触发计数查询来计算总数来实现的。由于这可能很昂贵(取决于使用的 Store),因此您可以返回Slice。 Slice仅知道下一个Slice是否可用,当遍历较大的结果集时可能就足够了。
排序选项也通过Pageable实例处理。如果只需要排序,则将org.springframework.data.domain.Sort参数添加到您的方法中。如您所见,返回List也是可能的。在这种情况下,不会创建构建实际Page实例所需的其他元数据(这反过来,这意味着不会发出本来必要的其他计数查询)。而是,它将查询限制为仅查找给定范围的实体。
要查明整个查询可获得多少页,您必须触发另一个计数查询。默认情况下,此查询源自您实际触发的查询。
限制查询结果
可以使用first或top关键字来限制查询方法的结果,这些关键字可以互换使用。可以将一个可选的数值附加到top或first以指定要返回的最大结果大小。如果省略该数字,则假定结果大小为 1.以下示例显示了如何限制查询大小:
例子 15.用Top和First限制查询的结果大小
User findFirstByOrderByLastnameAsc(); |
限制表达式还支持Distinct关键字。此外,对于将结果集限制为一个实例的查询,支持使用Optional关键字将结果包装到其中。
如果将分页或切片应用于限制查询分页(以及对可用页面数的计算),则会在限制结果内应用分页或切片。
通过使用Sort参数来限制结果与动态排序的组合,可以让您表达对最小的“ K”元素和对“ K”的最大元素的查询方法。
流查询结果
通过使用 Java 8 Stream
例子 16.用 Java 8 Stream
|
Stream可能包装了特定于底层数据存储的资源,因此在使用后必须将其关闭。您可以使用close()方法或使用 Java 7 try-with-resources块来手动关闭Stream,如以下示例所示:
例子 17.使用Stream
try (Stream<User> stream = repository.findAllByCustomQueryAndStream()) { |
异步查询结果
可以使用Spring 的异步方法执行能力异步运行存储库查询。这意味着该方法在调用时立即返回,而实际查询执行发生在已提交给 Spring TaskExecutor的任务中。异步查询执行与反应式查询执行不同,因此不应混为一谈。有关响应式支持的更多详细信息,请参阅 Store 特定的文档。以下示例显示了许多异步查询:
@Async |
(1) 使用java.util.concurrent.Future作为返回类型。
(2) 使用 Java 8 java.util.concurrent.CompletableFuture作为返回类型。
(3) 使用org.springframework.util.concurrent.ListenableFuture作为返回类型。