
大数据-Hive3.x
第 1 章 Hive 基本概念
什么是 Hive
- hive 简介
Hive:由 Facebook 开源用于解决海量结构化日志的数据统计工具。
Hive 是基于 Hadoop 的一个数据仓库工具,可以将结构化的数据文件映射为一张表,提供类 SQL查询功能. - Hive 本质
将 HQL 转化成MapReduce程序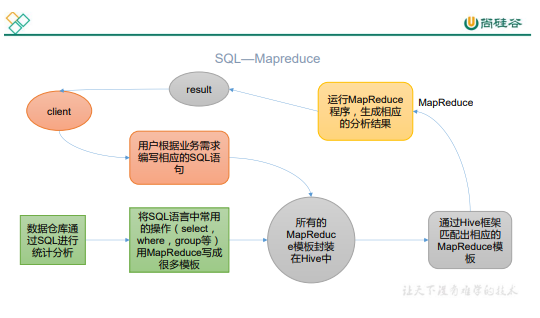
- Hive 处理的数据存储在
HDFS - Hive 分析数据底层的实现是
MapReduce - 执行程序运行在
Yarn上
Hive 的优缺点
- 优点
- 操作接口采用类 SQL 语法,提供快速开发的能力(简单、容易上手)。
- 避免了去写 MapReduce,减少开发人员的学习成本。
- Hive 的执行延迟比较高,因此 Hive 常用于数据分析,对实时性要求不高的场合。
- Hive 优势在于处理大数据,对于处理小数据没有优势,因为 Hive 的执行延迟比较高。
- Hive 支持用户自定义函数,用户可以根据自己的需求来实现自己的函数。
- 缺点
- Hive 的 HQL 表达能力有限
(1)迭代式算法无法表达
(2)数据挖掘方面不擅长,由于 MapReduce 数据处理流程的限制,效率更高的算法却无法实现。 - Hive 的效率比较低
(1)Hive 自动生成的 MapReduce 作业,通常情况下不够智能化
(2)Hive 调优比较困难,粒度较粗
Hive 架构原理
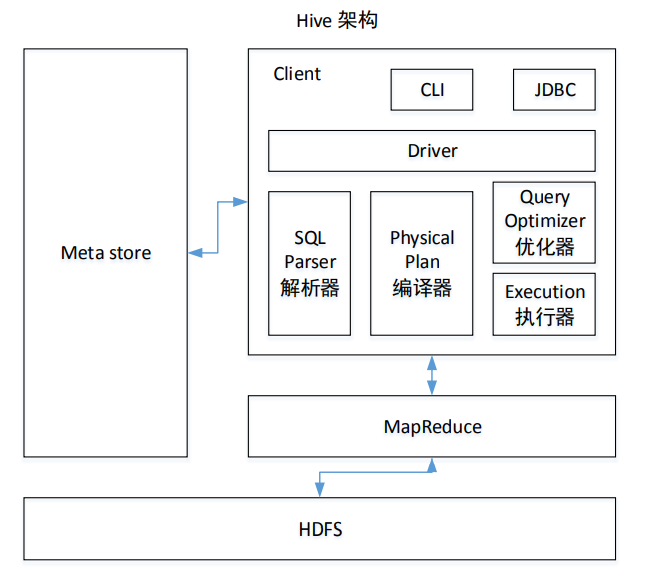
- 用户接口:Client
CLI(command-line interface)、JDBC/ODBC(jdbc 访问 hive)、WEBUI(浏览器访问 hive) - 元数据:Metastore
元数据包括:表名、表所属的数据库(默认是 default)、表的拥有者、列/分区字段、表的类型(是否是外部表)、表的数据所在目录等;默认存储在自带的 derby 数据库中,推荐使用 MySQL 存储 Metastore - Hadoop
使用 HDFS 进行存储,使用 MapReduce 进行计算。 - 驱动器:Driver
- 解析器(SQL Parser):将 SQL 字符串转换成抽象语法树 AST,这一步一般都用第
三方工具库完成,比如 antlr;对 AST 进行语法分析,比如表是否存在、字段是否存在、SQL
语义是否有误。 - 编译器(Physical Plan):将 AST 编译生成逻辑执行计划。
- 优化器(Query Optimizer):对逻辑执行计划进行优化。
- 执行器(Execution):把逻辑执行计划转换成可以运行的物理计划。对于 Hive 来说,就是 MR/Spark。
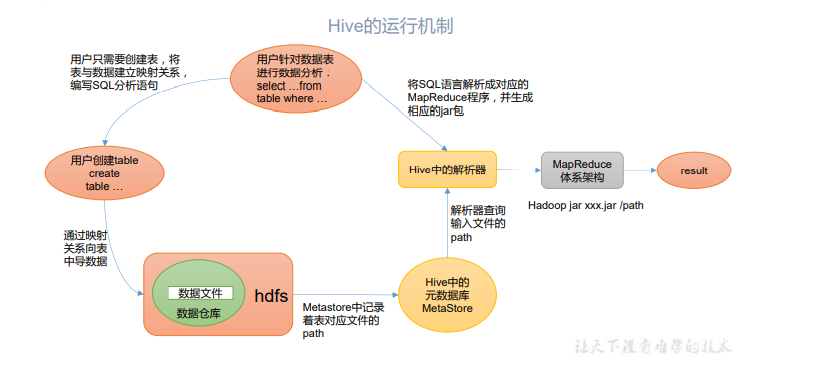
Hive 通过给用户提供的一系列交互接口,接收到用户的指令(SQL),使用自己的 Driver,结合元数据(MetaStore),将这些指令翻译成 MapReduce,提交到 Hadoop 中执行,最后,将执行返回的结果输出到用户交互接口。
Hive 和数据库比较
由于 Hive 采用了类似 SQL 的查询语言 HQL(Hive Query Language),因此很容易将 Hive 理解为数据库。其实从结构上来看,Hive 和数据库除了拥有类似的查询语言,再无类似之处。
本文将从多个方面来阐述 Hive 和数据库的差异。数据库可以用在 Online 的应用中,但是Hive 是为数据仓库而设计的,清楚这一点,有助于从应用角度理解 Hive 的特性。
查询语言
由于 SQL 被广泛的应用在数据仓库中,因此,专门针对 Hive 的特性设计了类 SQL 的查询语言 HQL。熟悉 SQL 开发的开发者可以很方便的使用 Hive 进行开发。
数据更新
由于 Hive 是针对数据仓库应用设计的,而数据仓库的内容是读多写少的。因此,Hive 中不建议对数据的改写,所有的数据都是在加载的时候确定好的。而数据库中的数据通常是需要经常进行修改的,因此可以使用 INSERT INTO … VALUES 添加数据,使用 UPDATE … SET 修改数据。
执行延迟
Hive 在查询数据的时候,由于没有索引,需要扫描整个表,因此延迟较高。另外一个导致 Hive 执行延迟高的因素是 MapReduce 框架。由于 MapReduce 本身具有较高的延迟,因此在利用 MapReduce 执行 Hive 查询时,也会有较高的延迟。相对的,数据库的执行延迟较低。当然,这个低是有条件的,即数据规模较小,当数据规模大到超过数据库的处理能力的时候,Hive 的并行计算显然能体现出优势。
数据规模
由于 Hive 建立在集群上并可以利用 MapReduce 进行并行计算,因此可以支持很大规模的数据;对应的,数据库可以支持的数据规模较小。
Hive安装
Hive安装地址
- Hive官网地址
http://hive.apache.org - 文档查看地址
https://cwiki.apache.org/confluence/display/Hive/GettingStarted - 下载地址
http://archive.apache.org /dist/hive/ - github地址
https://github.com/apache/hive
Hive安装部署
安装Hive
此hive版本由自己学习决定,路径目录同理
- 把
apache-hive-3.1.2-bin.tar.gz上传到 linux 的/opt/software目录下 - 解压
apache-hive-3.1.2-bin.tar.gz到/opt/module/目录下面tar -zxvf /opt/software/apache-hive-3.1.2-bin.tar.gz -C /opt/module/
- 修改
apache-hive-3.1.2-bin的名称为hive此处可自由决定是否修改
mv /opt/module/apache-hive-3.1.2-bin/ /opt/module/hive
- 修改
/etc/profile.d/my_env.sh,添加环境变量此处可以自己在
/etc/profile.d/目录下创建自己的环境变量,也可以直接配置在/etc/profile中sudo vim /etc/profile.d/my_env.sh
- 添加文件内容
HIVE_HOME
export HIVE_HOME=/opt/module/hive
export PATH=$PATH:$HIVE_HOME/bin - 解决日志Jar冲突
mv $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.jar $HIVE_HOME/lib/log4j-slf4j-impl-2.10.0.bak
- 初始化元数据
HIVE_HOME/bin/schematool -dbType derby -initSchema
启动并使用Hive
- 启动Hive
bin/hive
- 使用Hive
show databases;
show tables;
create table test(id int);
insert into test values(1);
select * from test;Hive默认使用的元数据库为
derby,开启Hive之后就用占用源数据库,且不与其他客户端共享数据,所以我们需要将Hive的元数据地址改为Mysql【单窗口运行可以,多窗口时则只有一个窗口能正常运行,其他窗口报错】
MySQL安装【如果自己已安装过MYSQL,可跳过】
检查当前系统是否安装过MySQL
rpm -qa|grep mariadb
如果系统安装了Mysql,则会出现相应的mysql版本,例如
mariadb-libs-5.5.56-2.el7.x86_64删除mysql命令
sudo rpm -e --nodeps mariadb-libs将
MySQL安装包拷贝到/opt/software目录下解压
MySQL安装包解压mysql安装包
tar -xf mysql-5.7.28-1.el7.x86_64.rpm-bundle.tar
在安装目录下执行 rpm 安装
注意:按照顺序依次执行
sudo rpm -ivh mysql-community-common-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-libs-compat-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-client-5.7.28-1.el7.x86_64.rpm
sudo rpm -ivh mysql-community-server-5.7.28-1.el7.x86_64.rpm删除
/etc/my.cnf文件中 datadir 指向的目录下的所有内容,如果有内容的情况下:
查看datadir的值:[mysqld] datadir=/var/lib/mysql
删除
/var/lib/mysql目录下的所有内容:注意执行命令的位置
sudo rm -rf /var/lib/mysql/*初始化数据库
sudo mysqld --initialize --user=mysql
查看临时生成的
root用户的密码sudo cat /var/log/mysqld.log
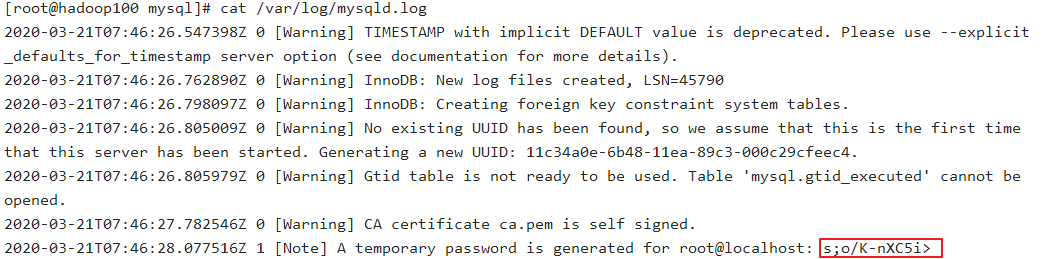
启动Mysql服务
sudo systemctl start mysqld
登录 MySQL 数据库
mysql -uroot -p
Enter password: 输入临时生成的密码必须先修改root用户密码,否则执行其他的操作会报错
mysql > set password = password("新密码");
修改 mysql 库下的 user 表中的 root 用户允许任意 ip 连接
mysql> update mysql.user set host='%' where user='root';
mysql> flush privileges;
Hive 元数据配置到 MySQL
拷贝驱动
将 MySQL 的 JDBC 驱动拷贝到 Hive 的 lib 目录下
cp /opt/software/mysql-connector-java-5.1.37.jar $HIVE_HOME/lib |
配置 Metastore 到 MySQL
在
$HIVE_HOME/conf目录下新建hive-site.xml文件vim $HIVE_HOME/conf/hive-site.xml
添加如下内容
<configuration>
<!-- jdbc 连接的 URL -->
<property>
<name>javax.jdo.option.ConnectionURL</name>
<value>jdbc:mysql://hadoop102:3306/metastore?useSSL=false</value>
</property>
<!-- jdbc 连接的 Driver-->
<property>
<name>javax.jdo.option.ConnectionDriverName</name>
<value>com.mysql.jdbc.Driver</value>
</property>
<!-- jdbc 连接的 username-->
<property>
<name>javax.jdo.option.ConnectionUserName</name>
<value>root</value>
</property>
<!-- jdbc 连接的 password -->
<property>
<name>javax.jdo.option.ConnectionPassword</name>
<value>000000</value>
</property>
<!-- Hive 元数据存储版本的验证 -->
<property>
<name>hive.metastore.schema.verification</name>
<value>false</value>
</property>
<!--元数据存储授权-->
<property>
<name>hive.metastore.event.db.notification.api.auth</name>
<value>false</value>
</property>
<!-- Hive 默认在 HDFS 的工作目录 -->
<property>
<name>hive.metastore.warehouse.dir</name>
<value>/user/hive/warehouse</value>
</property>
</configuration>登录MySQL
mysql -uroot -p自定义密码
新建Hive元数据
create database metastore;
quit;初始化Hive元数据库
schematool -initSchema -dbType mysql - verbose
再次启动Hive
- 启动Hive
bin/hive
- 使用hive
hive> show databases;
hive> show tables;
hive> create table test (id int);
hive> insert into test values(1);
hive> select * from test; - 启动另外一个窗口开启Hive
show databases;
show tables;
select * from aa;
使用元数据服务的方式访问 Hive
由于上方的配置只能服务器访问,此处操作用作外部访问,例如代码访问hive数据源
- 在
hive-site.xml文件中添加如下配置信息<!-- 指定存储元数据要连接的地址 -->
<property>
<name>hive.metastore.uris</name>
<value>thrift://hadoop102:9083</value>
</property> - 启动metastore
前台运行
hive --service metastore
2020-04-24 16:58:08: Starting Hive Metastore Server
注意: 启动后窗口不能再操作,需打开一个新的 shell 窗口做别的操作 - 启动hive
运行服务器客户端查看
bin/hive
使用JDBC方式访问Hive
- 在
hive-site.xml文件中添加如下配置信息<!-- 指定 hiveserver2 连接的 host -->
<property>
<name>hive.server2.thrift.bind.host</name>
<value>hadoop102</value>
</property>
<!-- 指定 hiveserver2 连接的端口号 -->
<property>
<name>hive.server2.thrift.port</name>
<value>10000</value>
</property> - 启动hiveserver2
bin/hive --service hiveserver2
- 启动beeline客户端(需要多等待一会)
bin/beeline -u jdbc:hive2://hadoop102:10000 -n atguigu
# 参数 |
登录成功界面
Connecting to jdbc:hive2://hadoop102:10000
Connected to: Apache Hive (version 3.1.2)
Driver: Hive JDBC (version 3.1.2)
Transaction isolation: TRANSACTION_REPEATABLE_READ
Beeline version 3.1.2 by Apache Hive
0: jdbc:hive2://hadoop102:10000>编写hive服务启动脚本(了解)
前台启动的方式导致需要打开多个 shell 窗口,可以使用如下方式后台方式启动
nohup: 放在命令开头,表示不挂起,也就是关闭终端进程也继续保持运行状态/dev/null:是 Linux 文件系统中的一个文件,被称为黑洞,所有写入改文件的内容 都会被自动丢弃2>&1: 表示将错误重定向到标准输出上&: 放在命令结尾,表示后台运行
一般会组合使用:nohup [xxx 命令操作]> file 2>&1 &,表示将 xxx 命令运行的结 果输出到 file 中,并保持命令启动的进程在后台运行。
[root@hadoop202 hive]$ nohup hive --service metastore 2>&1 & |
(1) 编写hiverserver脚本
为了方便使用,可以直接编写脚本来管理服务的启动和关闭
vim $HIVE_HOME/bin/hiveservices.sh |
!/bin/bash |
(2) 添加执行权限
[root@hadoop102 hive]$ chmod +x $HIVE_HOME/bin/hiveservices.sh |
(3) 启动Hive后台服务
[root@hadoop102 hive]$ hiveservices.sh start |
也可以简单启动
[root@hadoop202 hive]$ nohup hive --service metastore 2>&1 & |
Hive常用交互命令
[root@hadoop102 hive]$ bin/hive -help usage: hive |
-e不进入 hive 的交互窗口执行 sql 语句[root@hadoop102 hive]$ bin/hive -e "select id from student;"
-f执行脚本中 sql 语句
(1)在/opt/module/hive/下创建 datas 目录并在 datas 目录下创建hivef.sql文件(2)文件中写入正确的 sql 语句[root@hadoop102 datas]$ touch hivef.sql
select *from student;
(3)执行文件中的 sql 语句(4)执行文件中的 sql 语句并将结果写入文件中[root@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql
[root@hadoop102 hive]$ bin/hive -f /opt/module/hive/datas/hivef.sql > /opt/module/datas/hive_result.txt
Hive其他命令操作
- 退出 hive 窗口:
hive(default)>exit;
hive(default)>quit; - 在 hive cli 命令窗口中如何查看 hdfs 文件系统
hive(default)>dfs -ls /;
- 查看在 hive 中输入的所有历史命令
(1)进入到当前用户的根目录 /root 或/home/atguigu
(2)查看. hivehistory 文件[root@hadoop102 ~]$ cat .hivehistory
Hive 常见属性配置
Hive 运行日志信息配置
- Hive 的 log 默认存放在
/tmp/root/hive.log目录下(当前用户名下)
(1)修改/opt/module/hive/conf/hive-log4j2.properties.template文件名称为hive-log4j2.properties
(2)在hive-log4j2.properties文件中修改 log 存放位置=/opt/module/hive/logs
打印 当前库 和 表头
在 hive-site.xml 中加入如下两个配置:<property>
<name>hive.cli.print.header</name>
<value>true</value>
</property>
<property>
<name>hive.cli.print.current.db</name>
<value>true</value>
</property>
参数配置方式
- 查看当前所有的配置信息
hive>set;
- 参数的配置三种方式
(1)配置文件方式 默认配置文件:
hive-default.xml用户自定义配置文件:hive-site.xml注意:用户自定义配置会覆盖默认配置。另外,
Hive也会读入Hadoop的配置,因为Hive是作为Hadoop的客户端启动的,Hive的配置会覆盖Hadoop的配置。配置文件的设定对本 机启动的所有Hive进程都有效。(2)命令行参数方式
启动Hive时,可以在命令行添加-hiveconf param=value来设定参数。
例如:[root@hadoop103 hive]$ bin/hive -hiveconf mapred.reduce.tasks=10;
注意:仅对本次hive启动有效 查看参数设置:
hive (default)> set mapred.reduce.tasks; |
- (3)参数声明方式
可以在 HQL 中使用 SET 关键字设定参数
例如:hive (default)> set mapred.reduce.tasks=100;
注意:仅对本次 hive 启动有效。 查看参数设置
hive (default)> set mapred.reduce.tasks;
上述三种设定方式的优先级依次递增。即
配置文件<命令行参数<参数声明。注意某些系统级的参数,例如log4j相关的设定,必须用前两种方式设定,因为那些参数的读取在会话建立以前已经完成了。
Hive 数据类型
基本数据类型
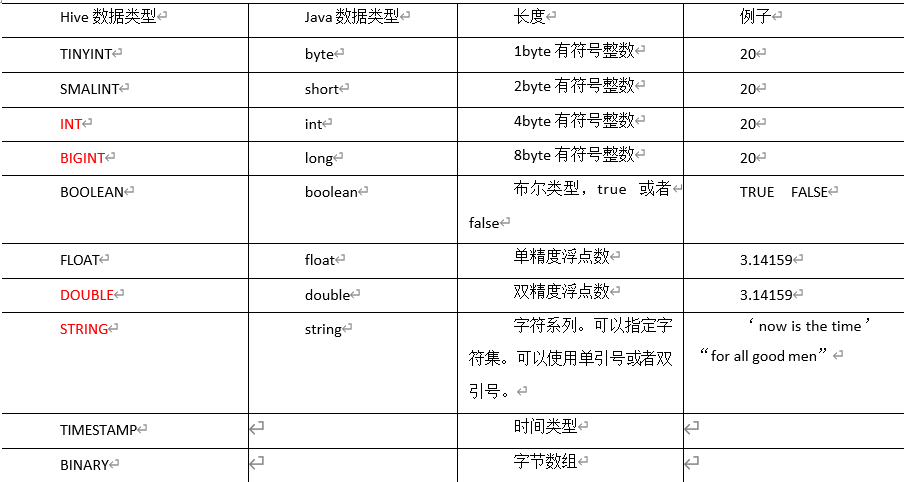
对于 Hive 的 String 类型相当于数据库的 varchar 类型,该类型是一个可变的字符串,不 过它不能声明其中最多能存储多少个字符,理论上它可以存储 2GB 的字符数。
集合数据类型
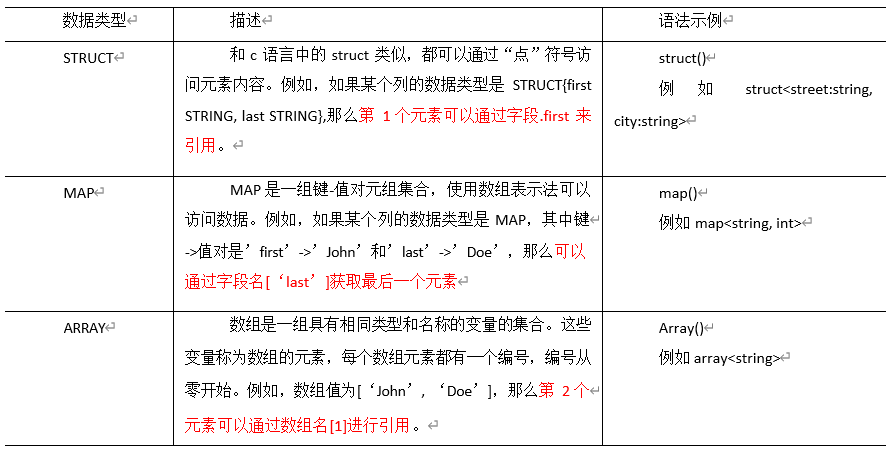
Hive 有三种复杂数据类型 ARRAY、MAP 和 STRUCT。ARRAY 和 MAP 与 Java 中的 Array 和 Map 类似,而 STRUCT 与 C 语言中的 Struct 类似,它封装了一个命名字段集合,复杂数据 类型允许任意层次的嵌套。
- 案例实操
(1)假设某表有如下一行,我们用 JSON 格式来表示其数据结构。在 Hive 下访问的格式为
(2)基于上述数据结构,我们在 Hive 里创建对应的表,并导入数据。 创建本地测试文件 test.txt
注意:MAP,STRUCT 和 ARRAY 里的元素间关系都可以用同一个字符表示,这里用“_”。
